dbt Cloud
dbt Cloud is supported via dedicated components. You can find them in the menu section Components:
-
kds-team.ex-dbt-cloud-apifor extracting data from dbt Cloud API -
kds-team.app-dbt-cloud-job-triggerfor triggering a dbt Cloud job remotely, and optionally, wait for the job results. In that case, the component stores artifacts as well.
dbt Cloud Trigger
Section titled “dbt Cloud Trigger”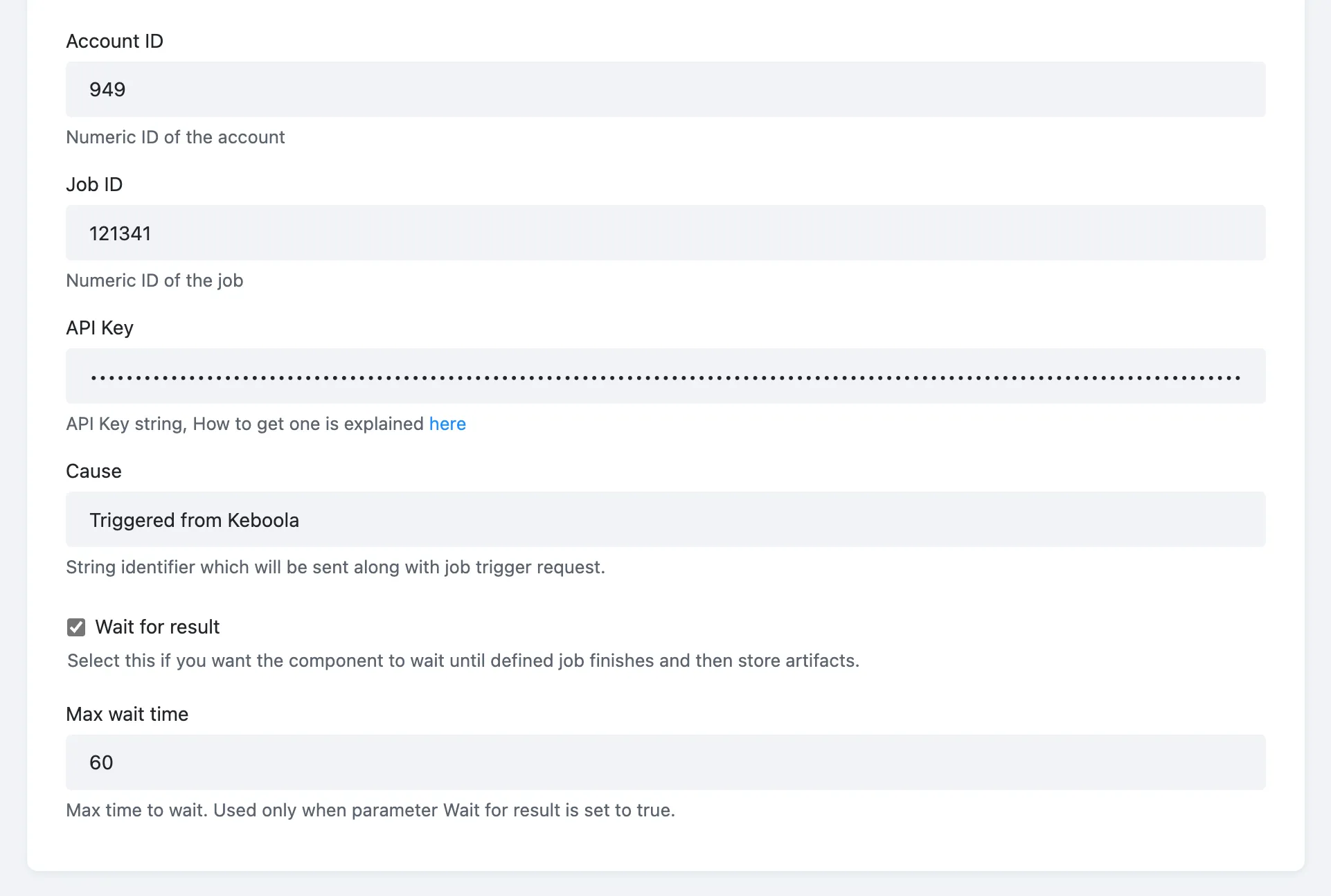
The component configuration is pretty straightforward. You must authorize the component by providing your Account ID, Job ID, and API key.
The component generates a status table called dbt_cloud_trigger storing the job trigger API response:

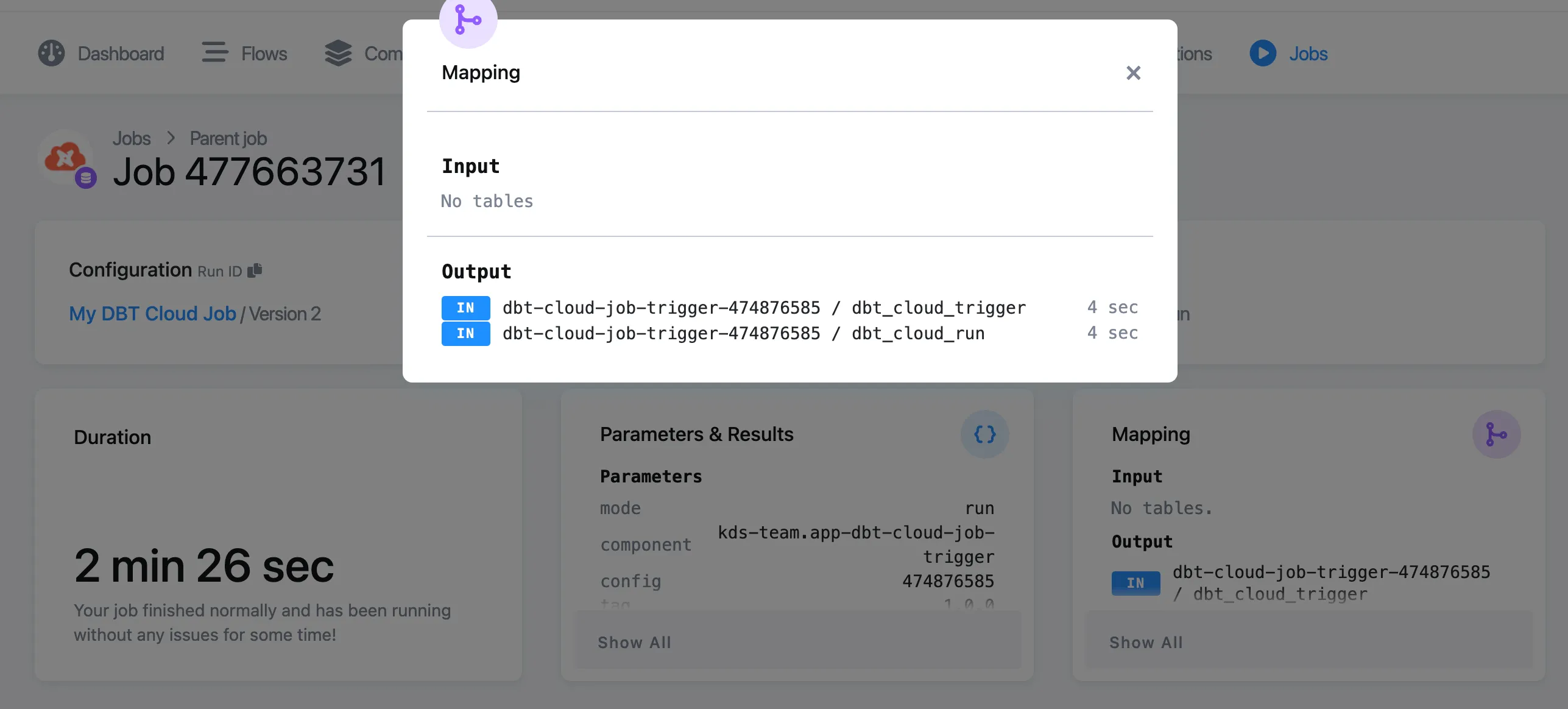
When Wait for result is selected, the component polls the status until the job ends. The component has a default wait time limit that can be optionally set to a different time. When the option Wait for result is used, the component extracts artifacts, stores them in the file storage, and additionally, produces a job result API call table:

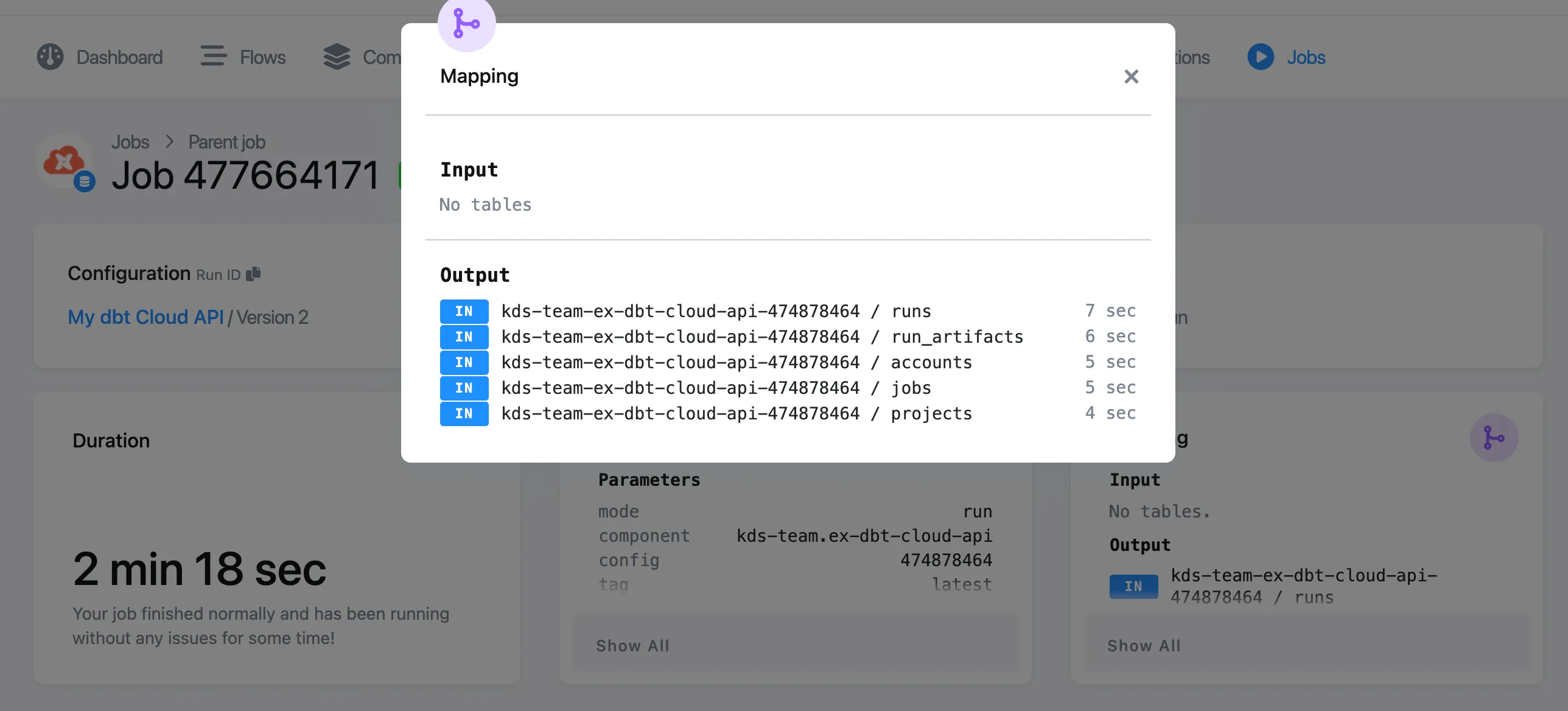
Both tables can be found in the storage, or accessed directly from the job result:
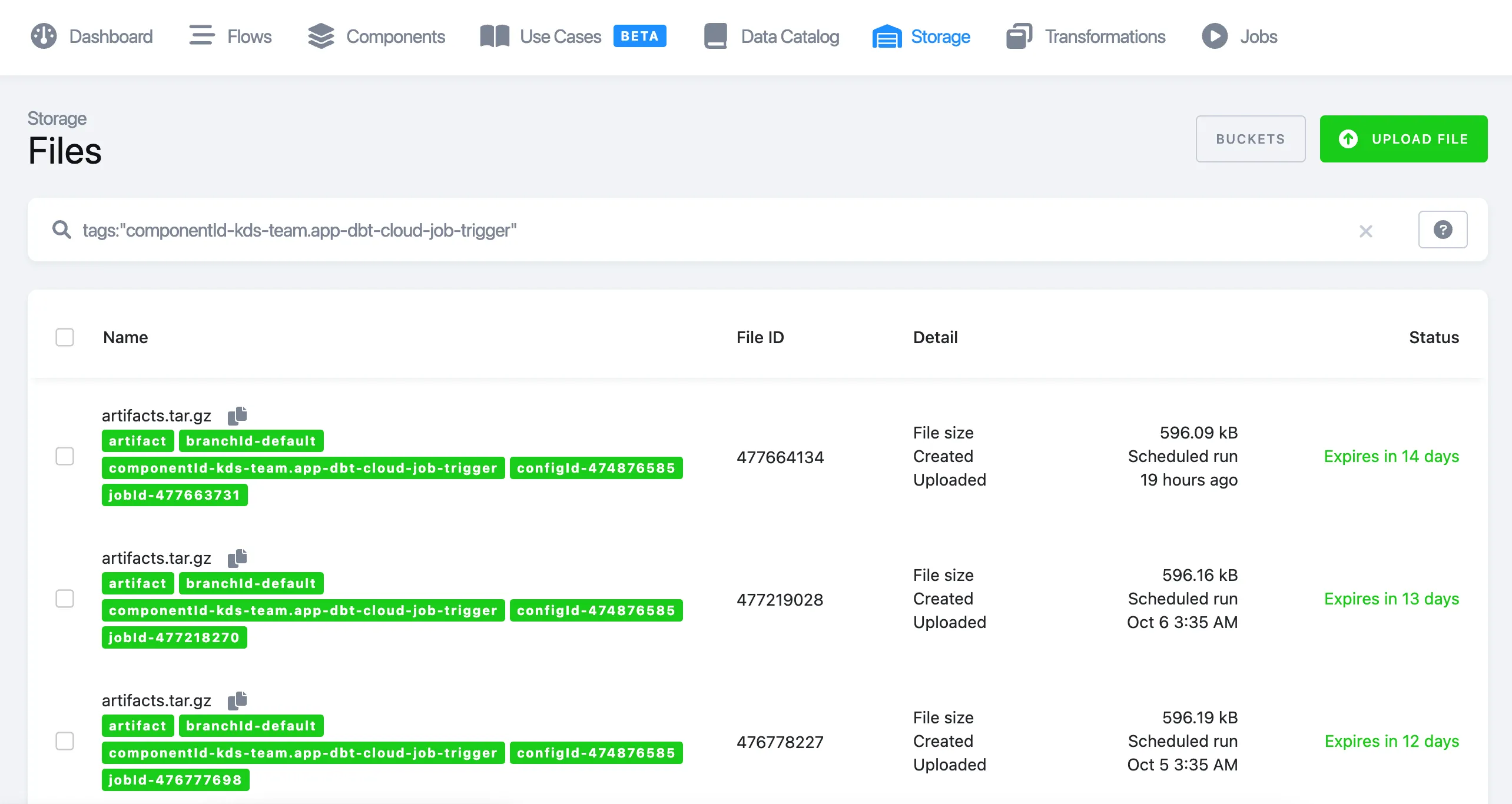
Artifacts can be found in the storage - files - search by tag:

Search by tag (component type or configuration ID):
tags:"componentId-kds-team.app-dbt-cloud-job-trigger"
Note: Please keep in mind that the base URL of the API call depends on the stack you are using: US vs. Azure EU vs. EU central.
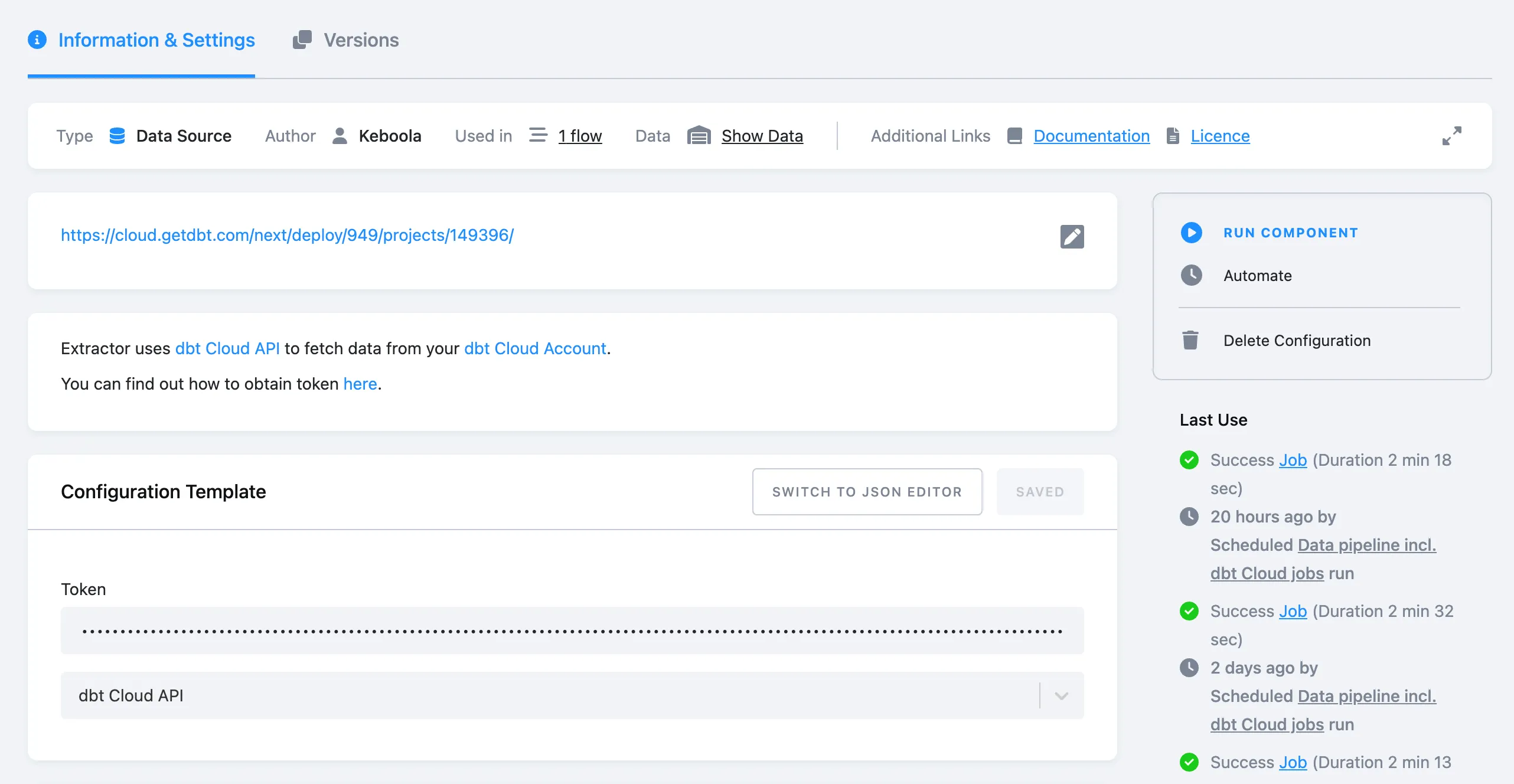
dbt Cloud API Source Component
Section titled “dbt Cloud API Source Component”The purpose of this data source connector is to extract and store the dbt Cloud API information (data is stored incrementally) for the following endpoints:
-
accounts
-
projects
-
jobs
-
runs
-
run_artifacts
To configure the source connector, enter the API token and select a default configuration:
You can access the data from Storage, or directly from the job detail screen: