DuckDB Transformation
DuckDB is an in-process analytical database designed for fast SQL analytics. It brings several advantages to Keboola transformations:
- In-process execution --- no external database server needed
- Columnar storage --- optimized for analytical queries
- Block-based orchestration with automatic dependency analysis
- Parallel execution of independent scripts within blocks
- Cost-effective alternative to cloud data warehouses for small to medium datasets
- Rich SQL dialect with modern quality-of-life extensions
Creating a DuckDB Transformation
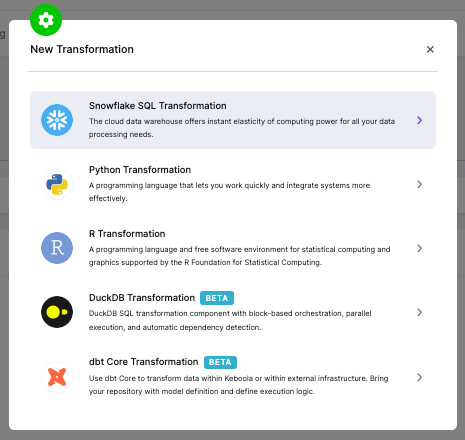
Section titled “Creating a DuckDB Transformation”To create a new DuckDB transformation, click New Transformation in the Transformations section and select DuckDB Transformation.
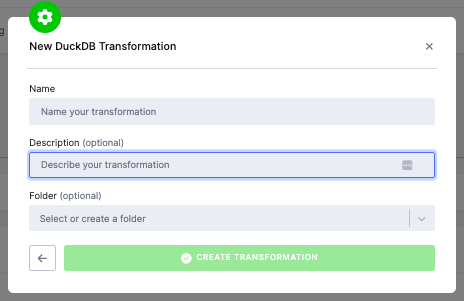
Name your transformation, optionally add a description and folder, and click Create Transformation.
Configuration
Section titled “Configuration”The configuration page allows you to set up input/output mappings, write SQL queries, and configure transformation settings.
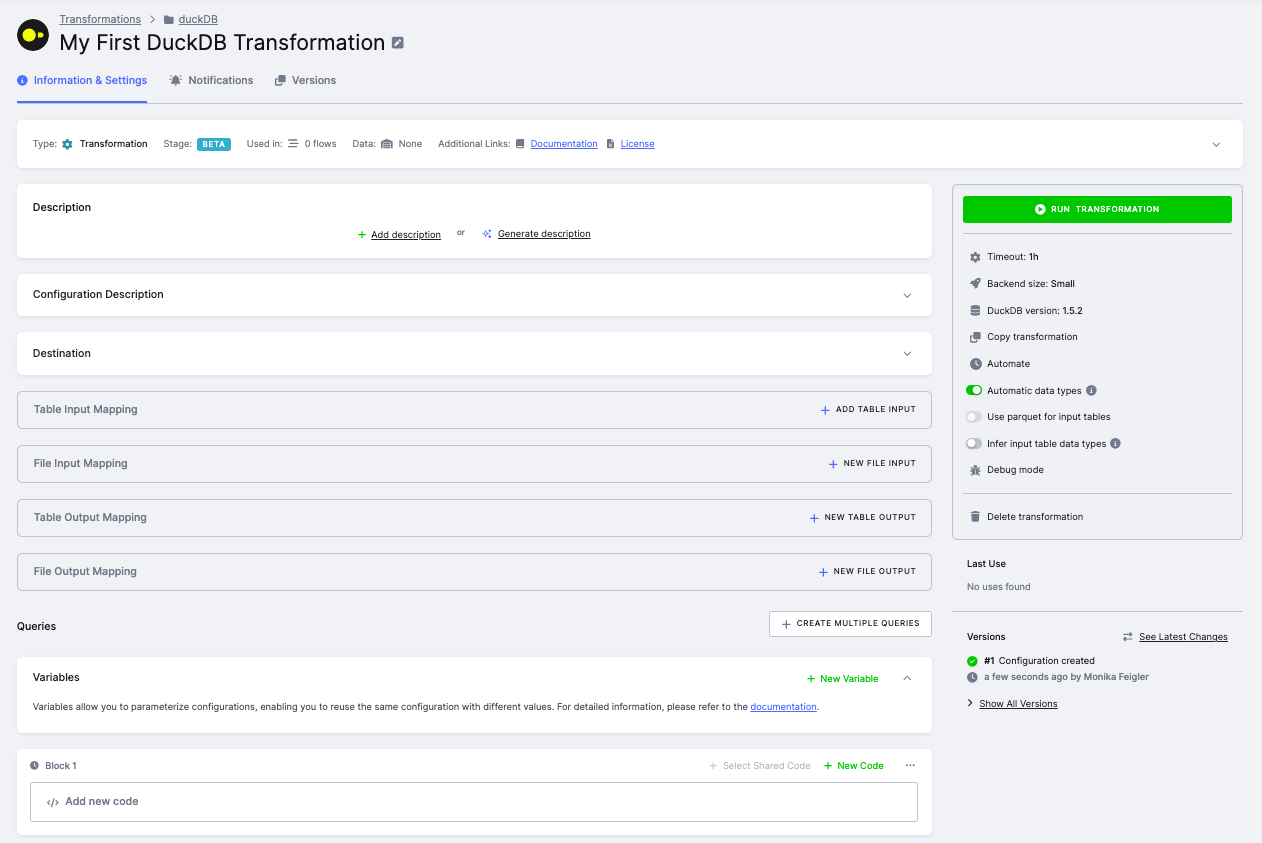
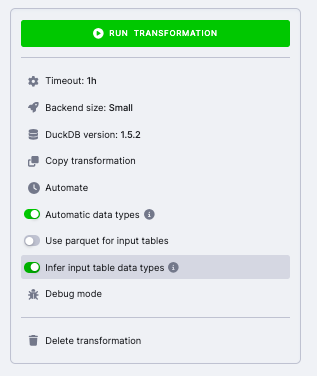
On the right side panel, you can configure:
- Timeout --- maximum execution time (default: 1 hour)
- Backend size --- amount of memory allocated for the transformation (see Dynamic Backends)
- DuckDB version --- select which DuckDB version to use (see DuckDB Version)
- Automatic data types --- automatically assign data types to output tables
- Use parquet for input tables --- use Parquet format instead of CSV for input data (see Parquet Format)
- Infer input table data types --- infer data types from input tables (see Infer Input Table Data Types)
- Debug mode --- enable debug logging for troubleshooting
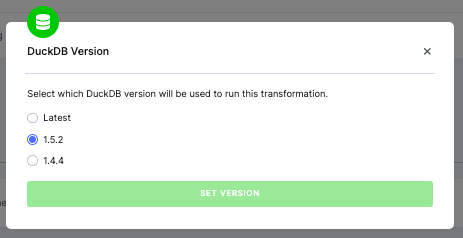
DuckDB Version
Section titled “DuckDB Version”You can select the DuckDB version used to run the transformation. Use latest (default) to always run on the most
recent supported version, or pin to a specific version (e.g., 1.5.2, 1.4.4) for stability. Each supported version
runs in its own isolated environment.
Block-Based Orchestration
Section titled “Block-Based Orchestration”DuckDB transformations use block-based orchestration for organizing and executing SQL code:
- Blocks are executed sequentially (one after another).
- Scripts (code pieces) within a block are executed in parallel when they have no dependencies on each other.
- The system uses SQLGlot to automatically analyze SQL and build a DAG (Directed Acyclic Graph) of dependencies.
- Execution order is automatically optimized based on the dependency analysis.
This means you can organize your transformation into logical blocks and let the system handle parallel execution where possible.
Sync Actions
Section titled “Sync Actions”DuckDB transformations provide four sync actions for debugging and visualization without running the full transformation:
- Syntax check (
syntax_check) --- validates your SQL syntax without executing any queries. Useful for catching errors before running the transformation. - Lineage visualization (
lineage_visualization) --- generates a markdown diagram of data dependencies, showing how tables flow through your transformation. - Execution plan visualization (
execution_plan_visualization) --- shows the planned execution order with blocks and batches, illustrating how the automatic DAG organizes your queries. - Expected input tables (
expected_input_tables) --- displays the list of input tables that the transformation expects based on the SQL analysis.
These actions are available from the transformation configuration page and are helpful for understanding and debugging complex transformations.
Dynamic Backends
Section titled “Dynamic Backends”You can change the backend size to allocate more memory for your transformation. The following sizes are available:
| Backend Size | Memory | Recommended For |
|---|---|---|
| XSmall | 8 GB | Small datasets, testing |
| Small (default) | 16 GB | Most use cases |
| Medium | 32 GB | Large datasets (5 GB+) |
| Large | 113.6 GB | Very large datasets (10 GB+) |
Start with the Small backend and scale up as needed based on your dataset size and query complexity.
Auto-Resource Detection
Section titled “Auto-Resource Detection”DuckDB automatically detects the available CPU and memory resources. You can also manually configure resource limits using the threads and max_memory_mb parameters in the transformation configuration.
Parquet Format
Section titled “Parquet Format”By default, input tables are loaded as CSV files. You can enable Parquet format for significantly better performance, especially with larger datasets.
Advantages of Parquet
Section titled “Advantages of Parquet”- Much faster processing than CSV
- Lower memory usage
- Columnar storage optimized for analytical queries
To enable Parquet, toggle the Use parquet for input tables option in the transformation settings.
Infer Input Table Data Types
Section titled “Infer Input Table Data Types”When working with non-typed (string-based) Storage tables, you can enable the Infer input table data types option. This feature instructs DuckDB to infer the actual data types of the input columns, so you can work with numeric, date, and boolean types directly in your SQL queries without manual casting.
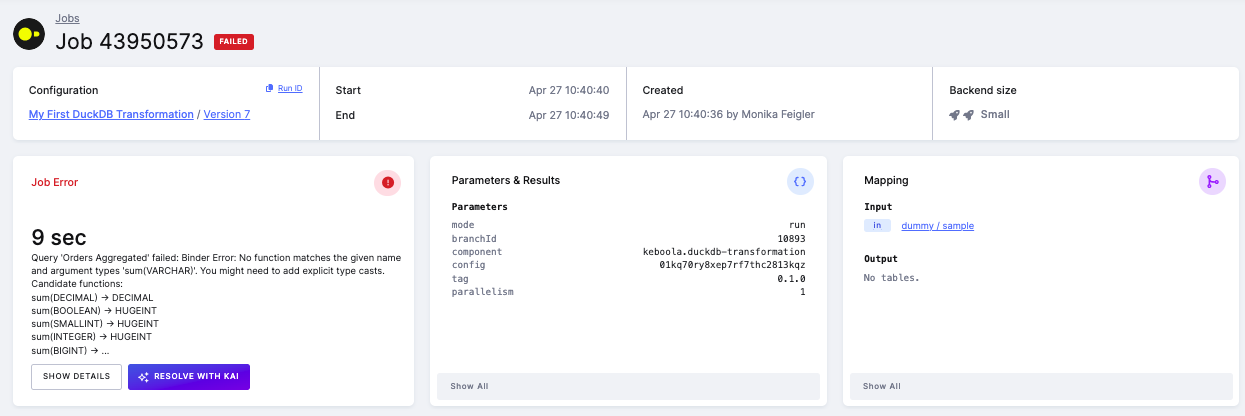
Why is this useful?
Keboola Storage tables can be non-typed (all columns stored as VARCHAR). Without type inference enabled,
all values in input tables are treated as strings, and functions like SUM() will fail because they expect numeric types.
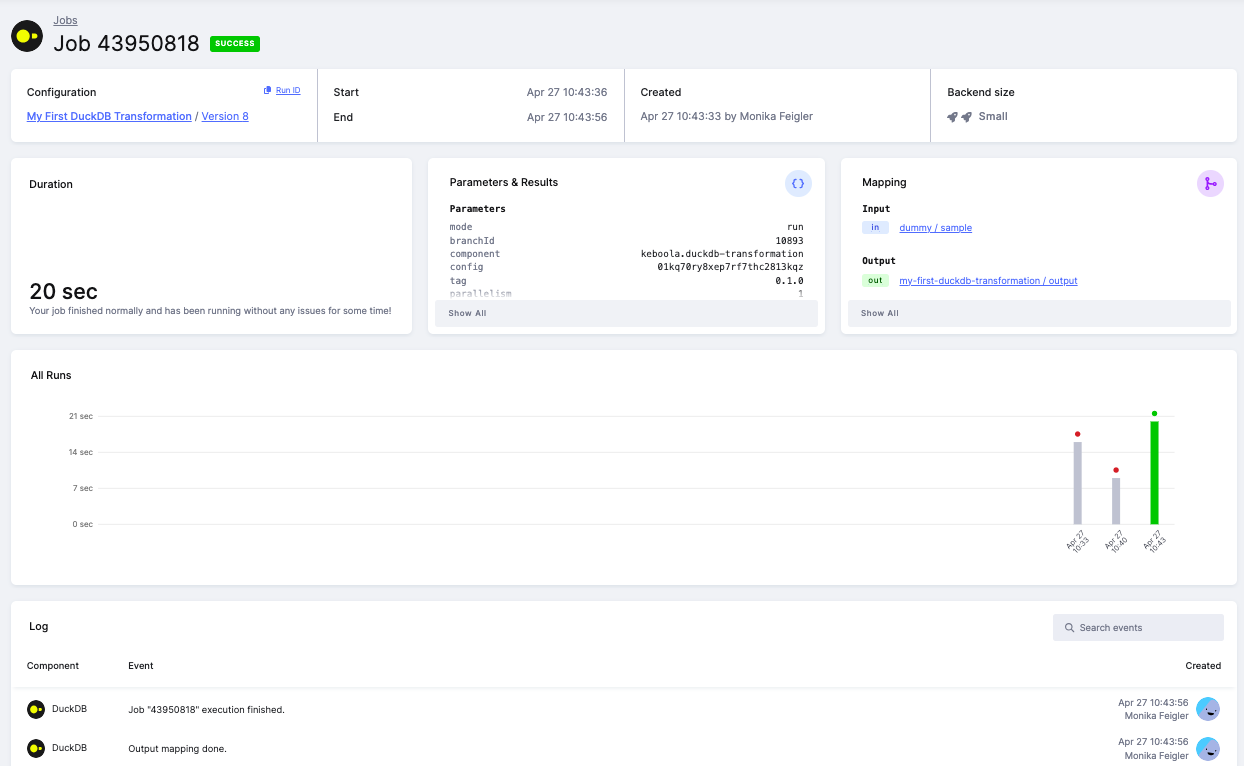
With Infer input table data types enabled, DuckDB automatically detects the correct types (e.g., INTEGER, FLOAT, DATE),
so aggregate functions and type-specific operations work as expected.
The output table then contains properly typed columns:
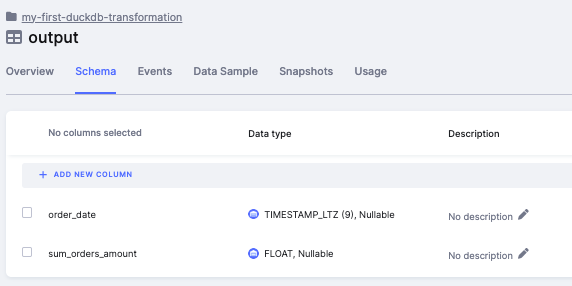
Example
Section titled “Example”To create a simple DuckDB transformation, follow these steps:
- Create a table in Storage by uploading the sample CSV file.
- Create an input mapping from that table, setting its destination to
sample(as expected by the DuckDB script). - Create an output mapping, setting its destination to a new table in your Storage.
- Copy & paste the below script into the transformation code
- Save and run the transformation
CREATE TABLE "output" ASSELECT "order_date", SUM("order_amount") AS "sum_orders_amount"FROM "sample"GROUP BY "order_date";
You can organize the script into blocks.
Best Practices
Section titled “Best Practices”Semicolons Between Statements
Section titled “Semicolons Between Statements”Each SQL statement in a DuckDB transformation must be terminated with a semicolon (;). If you have multiple statements
in a single script, make sure they are properly separated:
-- Correct: each statement ends with a semicolonCREATE TABLE "output_a" AS SELECT * FROM "input_a";
CREATE TABLE "output_b" AS SELECT * FROM "input_b";Missing semicolons will cause syntax errors.
Case Sensitivity
Section titled “Case Sensitivity”DuckDB handles identifier case differently than Snowflake:
Table names
Section titled “Table names”- Unquoted table names are converted to lowercase (e.g.,
SELECT * FROM MyTablereferencesmytable). - Quoted table names are case-sensitive (e.g.,
SELECT * FROM "MyTable"references exactlyMyTable).
Column names
Section titled “Column names”- Columns are always case-sensitive regardless of quoting (e.g.,
SELECT columnNameandSELECT ColumnNamerefer to different columns).
This is different from Snowflake, where unquoted identifiers become uppercase.
Best practices
Section titled “Best practices”- Use consistent casing for table and column names.
- When referencing tables with mixed case or special characters, always use quotes:
"TaBlE-stage". - Be aware that input table names are typically lowercase unless explicitly quoted.
Optimizing SQL Queries
Section titled “Optimizing SQL Queries”Filter and project early --- apply WHERE clauses as close to the source table as possible and select only the columns you need.
This reduces the amount of data DuckDB needs to scan.
-- Good: filter and project at the sourceSELECT id, name, priceFROM productsWHERE category = 'electronics' AND price > 100;Use EXPLAIN for performance analysis --- prefix your query with EXPLAIN to see the execution plan and identify expensive operations.
EXPLAIN SELECT product_category, SUM(price) AS total_revenueFROM salesWHERE sale_date >= '2023-01-01'GROUP BY product_categoryORDER BY total_revenue DESC;DuckDB SQL Extensions
Section titled “DuckDB SQL Extensions”DuckDB provides several quality-of-life SQL extensions that simplify common patterns:
GROUP BY ALL --- automatically groups by all non-aggregated columns:
SELECT product, category, SUM(sales)FROM ordersGROUP BY ALL;EXCLUDE --- select all columns except specific ones:
SELECT * EXCLUDE (password, ssn, credit_card)FROM users;ASOF JOIN --- useful for time-series data where timestamps do not match exactly:
SELECT s.player_id, s.score, s.score_time, w.temperature, w.conditionsFROM scores sASOF JOIN weather wON s.score_time >= w.timestamp;SUMMARIZE --- quick data profiling with min, max, null percentage, and unique counts:
SUMMARIZE SELECT * FROM my_table;Working With Data Types
Section titled “Working With Data Types”Keboola Storage tables store data in character types by default. When Infer input table data types is disabled,
all columns are loaded as VARCHAR. You need to cast values explicitly:
CREATE TABLE "result" ASSELECT CAST("amount" AS DECIMAL) AS "amount", CAST("created_at" AS TIMESTAMP) AS "created_at"FROM "source";When Infer input table data types is enabled, DuckDB automatically infers the correct types and you can use them directly.
Memory Management for Large Datasets
Section titled “Memory Management for Large Datasets”For datasets larger than 10 GB, configure DuckDB to use on-disk processing with PRAGMA settings:
PRAGMA memory_limit='8GB';PRAGMA temp_directory='/tmp/duckdb_temp';PRAGMA threads=4;PRAGMA enable_object_cache;Modular Transformations
Section titled “Modular Transformations”- Split complex transformations into smaller steps, each producing one output table.
- Use consistent naming conventions for output tables (e.g.,
stg_customers,fact_orders,dim_products). - Document complex business logic directly in the SQL code.
What DuckDB Is Not
Section titled “What DuckDB Is Not”DuckDB is an OLAP (Online Analytical Processing) database optimized for SELECT statements and analytical queries.
Avoid workflows with frequent INSERT and UPDATE operations. For transactional workloads, use a different backend such as Snowflake.
Real-World Example: CRM Data Transformation
Section titled “Real-World Example: CRM Data Transformation”The following example shows a typical DuckDB transformation processing CRM data (e.g., from HubSpot). It demonstrates
common patterns: TRY_CAST for safe type conversion, NULLIF for handling empty strings, and :: for type casting.
/* companies */CREATE TABLE "out_companies" ASSELECT "companyId", "name", "website", TRY_CAST(NULLIF("createdate", '') AS DATE) AS "createdate", "isDeleted"::BOOLEAN AS "isDeleted"FROM "companies";
/* contacts */CREATE TABLE "out_contacts" ASSELECT "canonical_vid", "firstname", "lastname", "email", TRY_CAST(NULLIF("createdate", '') AS DATE) AS "createdate", "hs_analytics_source" AS "email_source", "associatedcompanyid", "lifecyclestage"FROM "contacts";
/* deals */CREATE TABLE "out_deals" ASSELECT "dealId", "isDeleted"::BOOLEAN AS "isDeleted", "dealname", TRY_CAST(NULLIF("createdate", '') AS DATE) AS "createdate", TRY_CAST(NULLIF("closedate", '') AS DATE) AS "closedate", "dealtype", TRY_CAST(NULLIF("amount", '') AS DOUBLE) AS "amount", "pipeline", "dealstage", "hubspot_owner_id", "hs_analytics_source"FROM "deals";
/* pipeline stages */CREATE TABLE "out_stages" ASSELECT "stageId", "label", TRY_CAST(NULLIF("displayOrder", '') AS INT) AS "displayOrder", TRY_CAST(NULLIF("probability", '') AS DOUBLE) AS "probability", "closedWon"::BOOLEAN AS "closedWon"FROM "pipeline_stages";Key patterns used
Section titled “Key patterns used”TRY_CAST(NULLIF("column", '') AS TYPE)--- safely converts empty strings toNULLbefore casting. This avoids errors when the source data contains empty values."column"::BOOLEAN--- shorthand type cast syntax.- Each statement ends with a semicolon (
;) --- required when multiple statements are in a single script.
When to Use DuckDB vs. Snowflake
Section titled “When to Use DuckDB vs. Snowflake”Choose DuckDB for
Section titled “Choose DuckDB for”- Ad-hoc analysis and small to medium datasets
- Rapid prototyping of transformations
- Projects with limited budgets
- Datasets under a few terabytes
- Development and testing
Choose Snowflake for
Section titled “Choose Snowflake for”- Very large datasets (TB+)
- Complex enterprise workloads
- Sharing warehouses across multiple processes
- Maximum scalability
- Advanced Snowflake-specific features
Migrating from Snowflake to DuckDB
Section titled “Migrating from Snowflake to DuckDB”If you are migrating existing Snowflake transformations to DuckDB, see the detailed Snowflake to DuckDB Migration Guide.